Evolution of Compute and Big data
The primitive cloud, better known as “virtualization” evolved as a way to abstract the physical infrastructure which used to be manually deployed. The evolution of cloud computing from plain server virtualization is depicted in the flow below developed by Gartner in 2012 [1].
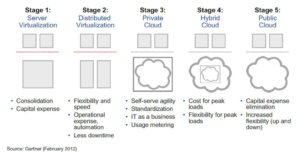
The first big step in compute evolution was from physical servers to virtual servers in data centers bringing higher server efficiency, hardware independence and uniformed environments. [2] This virtualization laid the foundation for cloud computing as a model to enable on-demand network access to a shared pool of resources that can be rapidly provisioned with minimal effort or interaction. The next big step in this journey is “Serverless computing” where the developers only need to worry about the business logic and the platform dynamically determines how much infrastructure is needed and then automatically provision or de-provision it to support the application. Here cloud instances are no longer allocated but only provisioned when an event occurs. An example of this is the “Internet of things” where sensor based devices react to triggers on the fly and the virtual machines in the cloud retrieve and serve up the information [3].
The advances in cloud computing are set to bring other technological advances. For eg. Machine learning is becoming more powerful than ever [4]. With all the companies moving to cloud based computing, there is so much data to train the models and specialize them for tasks like image processing, audio filtering etc. This has enabled the cloud providers to develop sophisticated Machine learning APIs which can be used off-the-shelf empowering application developers without having to gain expertise in underlying machine learning technologies. As machine learning becomes easier to work with, companies are moving from performing analytics to deep learning, uncovering new information and insights which are revolutionizing entire industries and business models.
The biggest challenge with cloud computing – which stores and retrieves data from offsite locations – is bandwidth. This problem is only going to increase with more and more physical objects coming online (a.k.a Internet of Things) to transmit and receive data. Here enters “Edge Computing” [5], the next big thing in cloud computing. It solves the bandwidth problem by keeping data at the edge of the cloud where the real world starts, i.e. in local computers and devices. For example, say you have a laptop and 2 phones at home. Now instead of all devices retrieving updates from the cloud themselves, what if the laptop could download the updates from the cloud and share it with the phones?
The principle of edge computing is to use the enormous computing power all around us and communicate internally [6]. This setup reduces communication lag times and cuts bandwidth by doing more computations locally. The prime candidate for Edge computing will be self-driving cars. They need signals from the cloud, but cannot rely on spotty internet network before accidents happen!
[1]https://www.stratoscale.com/blog/cloud/the-journey-from-virtualization-to-cloud-computing/
[3]https://www.cio.com/article/3244644/cloud-computing/serverless-the-future-of-cloud-computing.html
Users who have LIKED this post:
3 comments on “Evolution of Compute and Big data”
Comments are closed.
Prachi,
I really appreciated your analysis.
Although you say the prime candidate for edge will be cars, I wonder if they will not already be uninvited, or optimized, to only have the compute form heir drive systems?
What would your thoughts be on actually new devices specifically for edge enablement?
Similar to the devices and chips we mentioned in class form IBM. Would love you thoughts.
Best,
Zac
Towards the end of your post and as mentioned in the previous comment, you talk about the importance and requirement if edge enablement.
However the answer or future trend can really not be that simple. Where limited bandwidth and connection issues may push us for edge enablement but with new advancements in hardware and computer systems the cloud may become more important than ever.
A possible candidate for this argument is quantum computing. The great scale and rising demand for faster and more powerful processors may the cloud and data handling through it very necessary.
Hi Prachi,
Interesting post about the direction that cloud computing and virtualization are taking these days; thanks for sharing. As mentioned already in the comments, edge computing seems to be important for the practicality of virtualization and ‘serverless’ systems as the cloud scales upwards and bandwidth becomes an issue. I also wonder if wireless interference will be problematic for applications like autonomous vehicles – sometimes the issue isn’t whether or not there is signal reception, but rather whether it can be effectively transmitted to the target receiver (think about the last time you were in a huge crowd and you tried to load data on a mobile device). I’m curious if there’s a modular technology or some form of P2P network that would help with problems like this – that, or if the FCC will need to get involved.