
The Building Blocks of ML
Introduction to Machine Learning
Machine learning is the science of giving computers the ability to learn without being explicitly programmed. We are exposed to machine learning daily in our lives through applications such as Google searches, speech recognition and self-parking cars even without being aware of it [1]. However, machine learning is a field that even in the AI community among practitioners lacks a well-accepted definition to describe machine learning. Tom Mitchell defines machine learning the following way: “a computer program is said to learn from experience E, with respect to some task T, and some performance measure P, if its performance on T as measured by P improves with experience E” [2]. To illustrate this in the context of tyres selection for a Formula One car, the experience E, will be the experience of having racing the car. The task T, will be the task of analysing the tyres, and the performance measure P, will be the probability that correct type of tyres are selected for the race.
[3]
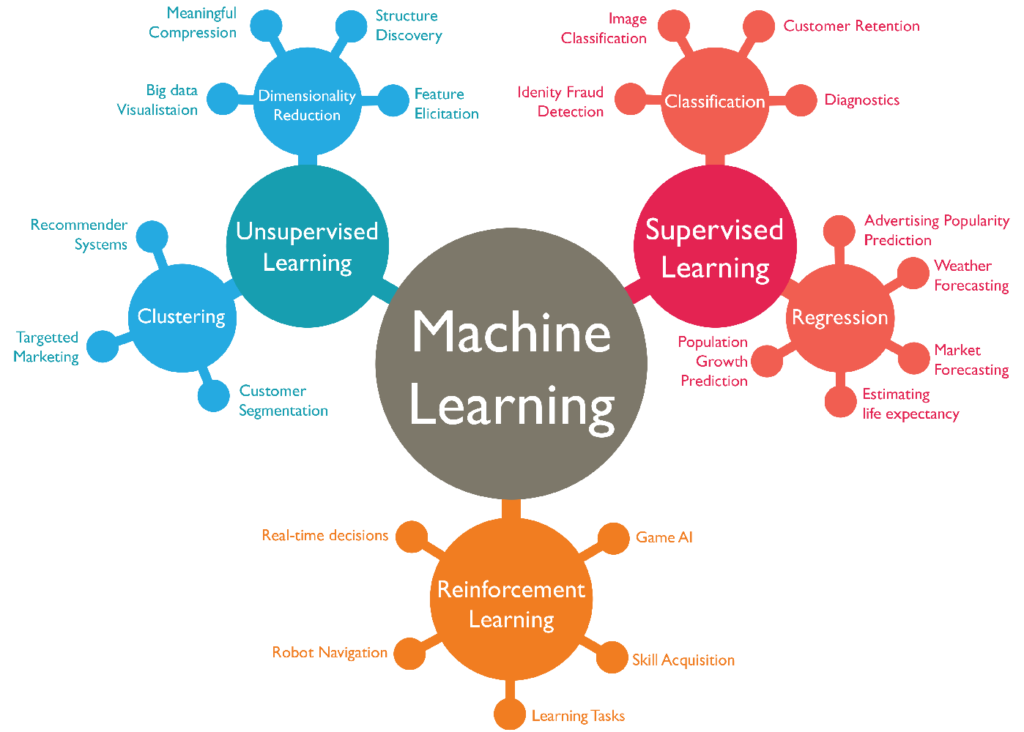
In general, there are three types of machine learning; supervised learning, unsupervised learning and reinforcement learning, where supervised learning and unsupervised learning are the two main types. In short, supervised learning is using training data to create a program that can make estimates by feeding training data into the machine learning algorithm to estimate parameters. The algorithm would discover underlying patters and figure out the relationship between different parameters, to make prediction of an estimate. As the training data set gets larger, the models train itself to becomes even more accurate. Unsupervised learning is when we know some parameters but we don’t know the correct answer for the output. However, the algorithm would figure out patterns and identify outliers.
The Building Blocks Behind Machine Learning
The challenge is to understand the fundamental building blocks of machine learning algorithms, machine learning techniques are built on formal statistical frameworks to make statistical modelling used to gather insights and learn from data, create and test algorithms to create accurate predictive models.
 [4]
[4]
I would like to illustrate the context of machine learning by an example of a Formula One car. A Formula One car in an incredibly complex machine with endless numbers of parameters that plays significant roles to maximize the physical capabilities of the car, lap after lap. You are sent out on a circuit that you have never been on before, and based on your previous experience, you are trying to figure out which tyres would provide the best performance. The conditions changes over the course of the race, tire wear out, temperature raises, but the driver has the ability to change to conditions. The tire compounds range from ultra-soft to hard, with four parameters such as tread, driving condition, grip and durability. In statistical terms, these are four sets of inputs to help you predict the optimal tyre for the conditions. The formal statistical learning framework would consist of four critical components; learner´s input, learner´s output, data-generalization model and measure of success [5].
These are the seven F1 tyre compounds
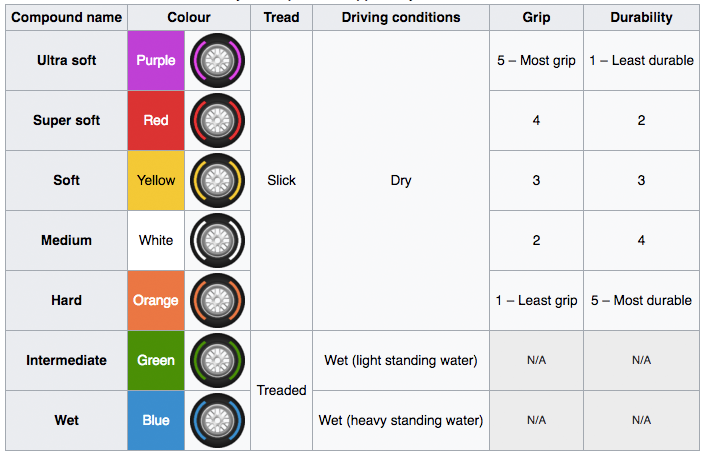
[6]
The learner´s input is an arbitrary set containing the objects to be labelled, the domain set can be represented using vector of features such as tread, driving condition, grip and durability. The label set contains predictions about the domain points, restricted by combinations of a four-element set. The training data is a sequence of combination of the four components to test the accuracy of the label set. The learner´s output is the prediction rule based on your previous experiences on similar tracks. The data-generalization model will generate a function based on the probability distributions of the domain set to choose the tyres with the best performance, and it is can be explicitly measured by the objective to reduce time. The error of the predictor can be determined by comparing laps to find the best set of tyres.
Conclusion
The aim of the machine learning algorithm is to minimize the model´s inaccuracy and prediction error to determine a probability distribution. In many cases the probability distribution is unknown, and the machine learning algorithm rely on agnostic learning, which is to find the best hypothesis to minimize the empirical error and generate training data that reliably reflect the unknown distribution [5].
The challenge of machine learning is to find relationships between sets of data, and an important aspect is to identify the gaps in incomplete data, clean and remove noise from messy datasets, before we can make it into reliable quality data of high value. As more dataset is analysed, the more it learns and it evolves over time, however most of the data gathered is unstructured data, which is typically data and text-heavy documents that is not organised or have a pre-defined data model.
References
[1] Ng, A. (2015). Machine Learning – Coursera
[2] Samuel, A. (1949).
[3] https://chatbotsmagazine.com/whats-machine-learning-it-s-expensive-slow-and-exclusive-for-now-4512c47352ee
[4] https://wall.alphacoders.com/by_sub_category.php?id=146225
[5] Gates, M. (2017). Machine Learning.
[6] https://en.wikipedia.org/wiki/Formula_One_tyres
Users who have LIKED this post:
2 comments on “The Building Blocks of ML”
Comments are closed.

Hi Chris,
Thank you very much for your very inspiring article. Most people write articles about the most common “Use Cases” or application opportunities of ML, but your topic on ML fascinated me. Nowadays a Formula One Car has over 200 built in sensors generating tons of data every second. Even in Germany, there have been articles stating the every Grand Prix becomes a highly complex Big-Data. Who collects more data and who better analyzed the data of his own Formula 1 car to make the right decisions e.g. on tires.
If we compare the data being processed of a Forma 1 car 10 years ago. It feels like there are ages of knowledge in between.
Chris, like Jens I really love your F1 metaphor. I find it interesteing that telemetry has been used in F1 since the 80s to stream live data from the car to engineers in the pit lane (https://www.forbes.com/sites/bernardmarr/2015/07/13/big-data-in-fast-cars-how-f1-and-nascar-compete-on-analytics/#641927177a34), and Jens comment made me think of what the role of the F1 driver is today, and in 10 years.
In an article by Fortune from 2015 Alan Peasland from Infiniti Red Bull Racing says that they try to keep what the driver sees of the data to a minimum as the drivers are already maxed out on their cognitive capacity. Similarly, Geoff McGrath, chief innovation officer at McLaren Applied Technologies argues that “The driver is still the best sensor we have.” (http://fortune.com/2015/11/12/big-data-formula-1-championship-race/) But how long will this last, and how will the requirements of the drivers change in the coming years?