Data at the Edge – but what does it mean?

The guest speaker Dr. Jeff Welser, Vice President and Lab Director at IBM Research Almaden, spoke about a new era of computing. He is certain that after the present era of Cloud and Mobile Computing the prevalent information technology paradigm is all about “Data at the edge”. One of his headlines states: “Data at the edge is changing how we look at data”. [1]
But why are new paradigms needed? What concepts do already exist and what beneficial characteristics do they have regarding tremendous data volume and their appropriate processing? And what about Cloud computing? These are a few questions to be answered to encourage a better understanding of the upcoming era of computing.
First of all, it needs to be identified why new paradigms are required. Over the last few years more and more devices were extended with processing elements and the ability to communicate, also known as the Internet of Things. These devices have sensors to collect data, which was not accessible before and through network-components they can communicate to central clouds or exchange data with each other. A huge benefit is the awareness of their surrounding and the potential to generate new services based on gathered data. Which in turn can lead to totally new business models. To do so some challenges need to be faced, for instance where to store and process these huge amounts of data? Clearly, cloud computing makes almost unlimited storage and processing capacity available (http://searchcloudcomputing.techtarget.com/tip/How-cloud-computing-will-change-capacity-management), but Jeff Welser also indicated the discrepancy between generated data and the bandwidth to deliver it to the cloud [1]. (https://www.forbes.com/sites/bernardmarr/2016/08/23/will-analytics-on-the-edge-be-the-future-of-big-data/#21dc86336445, http://www.infoworld.com/article/3204507/cloud-computing/data-at-the-edge-the-promise-and-challenge.html)
Edge Computing – Distributed Processing at the point of occurrence
An answer to this question of effectively using the data produced is a concept called Edge Computing, sometimes also referred to as Edge Analytics. The concept hereby is based on distribution, a central characteristic of the Internet of Things. Basic idea of the concept is to perform analysis and processing where the data is collected, which can have huge timely impacts and thereby benefit time-critical decisions, e.g. for self-driving cars, oxygen monitoring in mines or ensuring quality of factory & machinery processes. This approach is the opposite of Cloud Computing where processing and storage capacity as well as decision making are centralized. (http://www.infoworld.com/article/3204507/cloud-computing/data-at-the-edge-the-promise-and-challenge.html, https://www.forbes.com/sites/bernardmarr/2016/08/23/will-analytics-on-the-edge-be-the-future-of-big-data/#781d99536445)
Fog Computing – What’s different?
A similar concept and often interchangeably used is Fog Computing, where the computing and storage capabilities are pushed closer to the devices. The fog can be seen as an extension of the cloud. The difference to Edge Computing lies within the location of computing. While Fog Computing is extending the cloud and processing is located in the local network of an intelligent device, Edge Computing enables intelligent devices to process and analyze the data, where it originates. In other words, Fog Computing can benefit in the means of combining multiple datasets, whereas Edge Computing is only capable of analyzing a single dataset, determined through their differing location of processing. (https://www.linkedin.com/pulse/fog-computing-vs-edge-whats-difference-david-greenfield)
Moreover the OpenFog Consortium describes the fog’s ability to close the “cloud-to-thing contiunuum” (https://www.openfogconsortium.org/resources/#use-cases) and Cisco mentioned in its whitepaper Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are published in 2015, that “any device with computing, storage, and network connectivity can” [2] act as a bridge, also called fog node, from the smart things to the cloud. General purpose of these nodes is to monitor and analyze produced data in real-time and initiate appropriate actions to counteract any irregularities. [2]
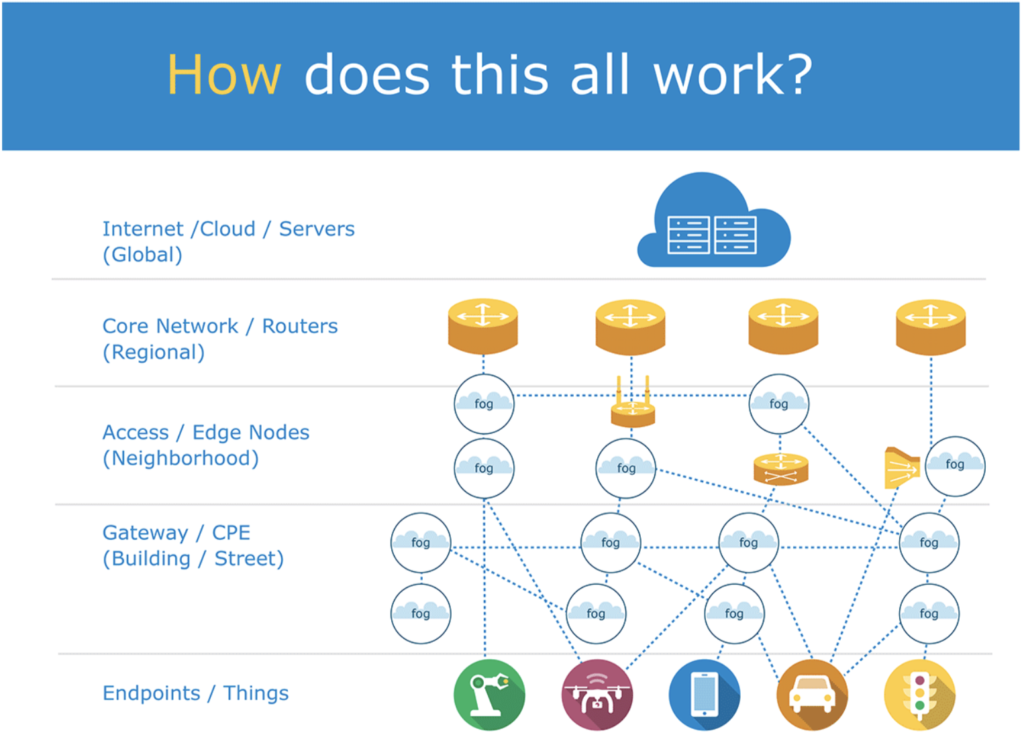
As visualized in the heading image the concept consists of several layers from the things to the cloud. Different tasks are assigned to these layers based on data as well as time criticality. Close nodes to the IoT devices have the smallest latency and can thereby respond fastest. Next level nodes are named Fog Aggregation Nodes, which are used to aggregate a larger amount of data and analyze the data sets of several devices. The cloud can in addition due to its capacity capabilities be used as long-term data storage to enable big data analytics as well as historical analysis. [2]
Beneficial aspects of the new era paradigm
A few beneficial aspects shall be named regarding the use of Edge or Fog Computing and thus enable Internet of Things and managing the explosion of data volume. Firstly, real-time analysis is benefiting from the processing power close to data collection, because of minimized latency. Secondly, it decreases workload on networks and less bandwidth needs to be provided for the data transfer to the cloud. Lastly, the concepts support higher data security, because data is not necessarily transferred to the cloud through insecure and public networks and thus sensitive data can be analyzed close to the device for instance in the company’s local network. [2] (https://www.openfogconsortium.org/resources/#use-cases)
Data at the Edge and Cloud – Supersession or Incorporation?
In my opinion Cloud Computing is still important for the aggregation of data from different sources and the analysis of huge data sets due to its almost unlimited capacity. Moreover the cloud is capable to maintain data for historical aspects. As described by Cisco and the OpenFog Consortium the paradigms are already incorporating with each other to exploit the benefits of the concepts. In conclusion data at the edge supports real-time computing and preprocessing of data thus not all of the collected data has to be transferred to the cloud.
References
[1] Wesler, Jeff: Cloud Platforms for the Cognitive Era, Stanford, 7 July 2017
[2] Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are, Cisco Systems, 2015. Web. 13 July 2017 (http://www.cisco.com/c/dam/en_us/solutions/trends/iot/docs/computing-overview.pdf)
Users who have LIKED this post: