A Map-Reduce Example
As a part of his presentation this week on Big Data, Srijan Kumar covered Map Reduce as a strategy for processing large datasets in a highly parallel environment. In previous weeks on this blog, I’ve covered a startup I co-founded in 2004 and discussed how things have changed in leading IT trends. This week, I’ll provide a practical example of how the Map Reduce algorithm could have been applied to problems we were solving.
Inspired by Paul Graham’s work on statistical spam detection[1], our first MVP was a simple bayesian classifier that predicted the phishiness of URLs that AOL users had reported as spam. This classifier operated on the “bag of words” representation of a URL. My co-founder and I trained the classifier on lists we manually curated. Bayesian classifiers require us to count how many times a given token/word has occurred in phishing versus non-phishing URLs. Though the dataset we were operating weren’t large enough to require distributed processing, and even though Google is moving away from MapReduce [2], applying the algorithm is still instructive. The example code below was written for this blog post and is not the original classifier code.
First we need to provide a map function that will operate on incoming lines (URLs) and emit tokens. We wanted to track tokens at different locations in the URLs separately (domain, port, query string, etc), so our tokenizer creates pseudo-tokens by prepending a category to a token value. Here’s some sample code in Python 3:
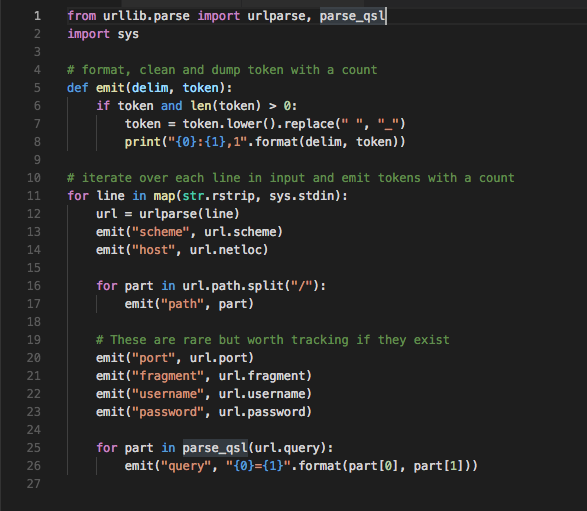
Here’s the output of the code applied to this URL:
scheme:https,1 host:www.quora.com,1 path:how-much-does-netflix-spend-on-amazon-aws,1 query:share=1,1
sort < raw_tokens.txt > sorted_tokens.txt
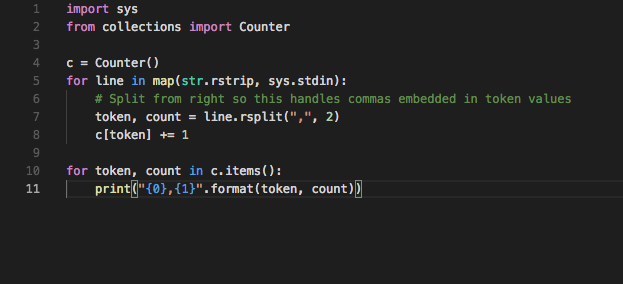
Finally, we can feed the combined output of our reducer functions to our classifier to be used for making predictions.
References
[1] http://www.paulgraham.com/better.html
[2] http://www.datacenterknowledge.com/archives/2014/06/25/google-dumps-mapreduce-favor-new-hyper-scale-analytics-system
[3] https://gist.github.com/ajstiles/58dd74728f0ef5fab9d8fe02fb425f7d
[4] https://gist.github.com/ajstiles/1539549c897ce9c1182c8149f7ba0482


