Validity and Veracity
Simon Chan’s discussion on the advantages and disadvantages to startups and incumbents was very interesting. I’d like to explore this further in the context of the disadvantages to incumbents in terms of the usefulness of their available data and in the advantages to incumbents in terms of their data volume.
First, the disadvantages.
A 2016 Data Science Report by Crowdflower[1] indicated that many data scientists spend most of their time cleaning up data:
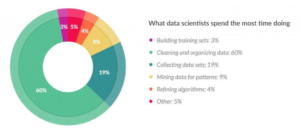
This image has been making rounds on LinkedIn in some oil & gas data science circles. A writer for Infoworld even jokes that data scientists can feel like “digital janitors” because they spend so much of their time cleaning up data to make it useful[2]. This echoes Simon Chan’s comment that Validity and Veracity are two common “Big Data Imperfections.”
According to a report by PWC, top global industrial incumbents are spending upwards of $907 G per year, or 5% of revenue, to improve their digital environment, roughly 1.5x the market cap of GOOG[3][4]. That is a significant cash outlay just to catch up with the tech companies in getting their data in a format that can lend itself to analysis by the types of algorithms that tech companies are already using. If incumbent companies do learn to make use of their data, the prize is large. A 2013 report from the International Institute for Analytics[5] provides a number of case studies – in one example, UPS saved 8.4 million gallons of fuel per year.
Startups face the opposite problem – that of data availability. While they may have unique analytics solutions, according to the same PWC report Data Loss and Unauthorized Data Extraction / Modification were two of the top three concerns for large companies around data, with only Operational Disruption taking a higher position. This does not paint a picture of companies eager to provide access to their data for startups that they may not trust.
On the other hand, large incumbents started after the Web 1.0 revolution (Google, Facebook, etc.) have a unique advantage. They have grown up with data structures that favor analysis, unlike the industrial giants. This is especially important in the data arena because more data means better tuned algorithms, which in turn means better products, and therefore more customers / data, ad infinitum[6]. This integration is reminiscent of the vertical integration that favored the early industrial monopolies, and even the Economist is calling data the new oil[7]. The algorithms are simple, but the tuning parameters and error estimates become more reliable and therefore more predictive with larger data sets[8]. This so-called “data network effect” is well-documented [9].
[1]https://visit.crowdflower.com/data-science-report.html
[2]http://www.infoworld.com/article/3047584/big-data/hottest-job-data-scientists-say-theyre-still-mostly-digital-janitors.html?lipi=urn%3Ali%3Apage%3Ad_flagship3_profile_view_base_recent_activity_details_all%3BpnghWay9TlOGzd6NSyviyQ%3D%3D
[3]https://www.pwc.com/gx/en/industries/industries-4.0/landing-page/industry-4.0-building-your-digital-enterprise-april-2016.pdf
[4]https://www.google.com/finance?cid=694653
[5]http://docs.media.bitpipe.com/io_10x/io_102267/item_725049/Big-Data-in-Big-Companies.pdf
[6]https://www.wired.com/story/ai-and-enormous-data-could-make-tech-giants-harder-to-topple/
[7]https://www.economist.com/news/leaders/21721656-data-economy-demands-new-approach-antitrust-rules-worlds-most-valuable-resource
[8]http://www-bcf.usc.edu/~gareth/ISL/
[9]http://mattturck.com/the-power-of-data-network-effects/
